Ingin tahu cara membuat model prediktif yang akurat? Artikel ini akan membantu Anda memahami pembelajaran mesin yang diawasi. Ini adalah teknik pembelajaran mesin yang populer di banyak industri. Mempelajari konsep dasar, cara kerja, dan komponen utamanya. Anda juga akan mempelajari cara menerapkan model prediktif dari algoritma pembelajaran yang diawasi. Memahami pembelajaran mesin yang diawasi akan memberi Anda lebih banyak pengetahuan. Kami tahu cara membangun model prediksi yang efektif dan akurat. Artikel ini akan menjadi panduan yang berguna untuk Anda.

Ikhtisar Model Pembelajaran Mesin yang Diawasi
Sebelum kita mendalami pembelajaran mesin yang diawasi, mari kita pelajari beberapa konsep dasar. Pembelajaran mesin adalah cabang ilmu komputer yang berfokus pada pengembangan algoritma. Algoritma ini memungkinkan sistem untuk melakukan tugas berdasarkan pola data tanpa instruksi khusus.
Konsep Dasar Pembelajaran Mesin
Komputer dapat “belajar” dari pengalaman dan meningkatkan kinerjanya. Algoritme pembelajaran mesin menggunakan data pelatihan untuk membangun model prediktif. Model ini kemudian diterapkan pada data baru.
Perbedaan antara Pembelajaran yang Diawasi dan Tanpa Pengawasan
Ada dua jenis utama pembelajaran mesin: pembelajaran yang diawasi dan pembelajaran tanpa pengawasan. Perbedaan utamanya adalah apakah label tersedia di data pelatihan. Dalam pembelajaran yang diawasi, data pelatihan diberi label dengan jelas. Namun, dalam pembelajaran tanpa pengawasan, data pelatihan tidak memiliki label.
Peran Data dalam Pembelajaran yang Diawasi
Dalam pembelajaran yang diawasi, kualitas dan keterwakilan data pelatihan sangatlah penting. Data harus mempunyai karakteristik yang relevan dan tujuan yang jelas. Hal ini memungkinkan model mempelajari pola dan membuat prediksi akurat berdasarkan data baru.
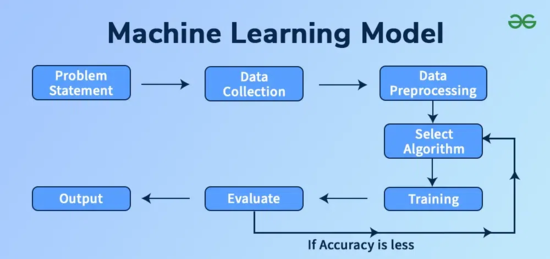
Cara Kerja Model Pembelajaran Mesin yang Diawasi
Dalam *proses pembelajaran yang diawasi*, model pembelajaran mesin belajar dari *data masukan*. Tujuannya adalah untuk menghasilkan keluaran prediksi yang benar. Pertama, kumpulan data yang relevan dikumpulkan dan dibagi menjadi dua bagian: data pelatihan dan data pengujian.
Latih model menggunakan data pelatihan menggunakan algoritma yang sesuai. Selama pelatihan model, algoritme mempelajari hubungan antara masukan dan keluaran yang diinginkan. Model tersebut kemudian diuji menggunakan data uji dan kinerjanya dievaluasi. Jika model menunjukkan hasil yang baik, maka model siap digunakan. *Prediksi keluaran* baru dibuat dari *input data* baru. Proses ini diulangi hingga model mencapai akurasi yang diinginkan.
Komponen Utama Model Prediksi yang Diawasi
Untuk membuat model prediksi yang akurat, Anda perlu mengingat beberapa hal. Anda memiliki kumpulan data untuk pelatihan dan pengujian, algoritme pembelajaran mesin yang sesuai, dan fungsi evaluasi model untuk mengevaluasi kinerja prediktif.
Pelatihan dan Pengujian Kumpulan Data
Kumpulan data berkualitas tinggi sangatlah penting. Ini adalah dasar bagi model untuk mempelajari dan membuat prediksi yang benar. Kumpulan data dibagi menjadi dua bagian: kumpulan data pelatihan untuk pelatihan dan kumpulan data pengujian untuk evaluasi.
Algoritma Pembelajaran
Memilih algoritma pembelajaran mesin yang tepat sangatlah penting. Algoritma seperti regresi linier, pohon keputusan, hutan acak, dan mesin vektor pendukung biasanya digunakan.
Fungsi Evaluasi Model
Untuk mengetahui keakuratan suatu model diperlukan fungsi evaluasi model seperti presisi, presisi, recall, dan skor F1. Fitur-fitur ini menunjukkan performa model dan membantu Anda meningkatkan model Anda.
Jenis Algoritma Pembelajaran yang Diawasi
Dalam dunia pembelajaran mesin yang diawasi, ada banyak algoritma untuk membangun model prediktif yang akurat. Ada dua kategori utama: algoritma klasifikasi dan algoritma regresi. Algoritma klasifikasi digunakan untuk memprediksi kategori, seperti apakah suatu email adalah spam atau bukan.
Algoritme regresi digunakan untuk memprediksi angka-angka seperti harga real estat. Pohon keputusan adalah algoritma klasifikasi yang umum. Algoritma ini menciptakan aturan berbasis pertanyaan untuk mengklasifikasikan data. Mesin vektor pendukung digunakan dalam masalah klasifikasi, terutama bila terdapat batasan yang jelas antar kelas.
Algoritma regresi yang umum digunakan adalah regresi linier dan regresi logistik. Regresi linier diterapkan pada nilai kontinu, dan regresi logistik diterapkan pada nilai biner atau kategorikal. Memilih algoritme yang sesuai bergantung pada data Anda dan tujuan model prediktif Anda. Setiap algoritma mempunyai kelebihan dan kekurangan. Hal ini penting untuk dipahami agar dapat memilih yang tepat untuk bisnis Anda.
Langkah-Langkah Membangun Model Prediktif yang Akurat
Membangun model prediktif yang akurat memerlukan beberapa langkah penting. Pertama, kumpulkan dan persiapkan data Anda dengan cermat. Proses pra-pemrosesan data seperti pembersihan dan pemformatan sangatlah penting. Silakan masukkan nilai yang hilang dengan benar. Selanjutnya, pilih fungsi yang terkait dengan model Anda. Fitur yang sesuai dapat membuat model Anda lebih baik.
Memilih Algoritma yang Sesuai
Langkah selanjutnya adalah memilih algoritma pembelajaran mesin yang sesuai. Ada beberapa algoritma populer seperti regresi linier dan hutan acak. Yang mana yang Anda pilih tergantung pada masalah yang dihadapi.
Proses Pelatihan dan Validasi
Setelah data disiapkan dan algoritma dipilih, saatnya melatih model. Pada fase ini, model belajar dari data pelatihan. Selanjutnya, lakukan validasi silang pada data pengujian untuk memeriksa keakuratannya. Proses optimasi model juga penting untuk meningkatkan kinerja prediksi. Ikuti langkah-langkah berikut untuk membangun model prediksi yang akurat.
Model ini dapat digunakan di berbagai industri. Menerapkan Model di Berbagai Industri Alat pembelajaran mesin yang diawasi sangat berguna di berbagai industri. Ini termasuk *Perkiraan Bisnis*, *Analisis Kesehatan*, dan *Deteksi Penipuan*. Aplikasi pembelajaran mesin memiliki potensi besar.
Dalam dunia bisnis, model ini berguna untuk menganalisis tren pasar. Memprediksi permintaan pelanggan dan mengoptimalkan investasi. Di bidang perawatan kesehatan, alat-alat ini dapat membantu mengidentifikasi risiko penyakit sejak dini dan merekomendasikan pengobatan yang lebih tepat.
Penerapan pembelajaran mesin juga efektif dalam *deteksi penipuan* di bidang keuangan. Model ini memantau transaksi, mengidentifikasi pola mencurigakan, dan mencegah kerugian akibat penipuan. Kemampuan beradaptasi yang hebat membuat model pembelajaran mesin yang diawasi menjadi sangat berharga. Hal ini meningkatkan efisiensi dan keakuratan prediksi. Ini membantu Anda membuat keputusan bisnis yang lebih tepat.
Teknik Pengoptimalan yang Diawasi untuk Pembelajaran
Mesin Untuk membuat model prediktif terawasi yang akurat, penting untuk menggunakan teknik pengoptimalan yang tepat. Ada beberapa teknik penting untuk meningkatkan kinerja pengoptimalan model. Ini termasuk pengoptimalan parameter, validasi silang, dan rekayasa fitur.
Penyetelan Hyperparameter
Penyetelan hyperparameter adalah proses menemukan parameter optimal untuk algoritme pembelajaran mesin. Parameter ini memiliki dampak signifikan terhadap performa model. Oleh karena itu, penting untuk melakukan penyesuaian dengan benar. Ada beberapa cara umum untuk menyetel hyperparameter. Contohnya termasuk pencarian grid, pencarian acak, dan optimasi Bayesian.
Validasi Silang
Validasi silang membantu Anda mengevaluasi model Anda menggunakan data independen. Hal ini penting untuk melihat performa model Anda di dunia nyata, bukan hanya pada data pelatihan Anda. Validasi silang K-fold dan validasi silang berlapis merupakan metode validasi silang yang umum digunakan.
Rekayasa Fitur
Rekayasa fitur adalah proses membuat, memilih, dan memodifikasi fitur dalam kumpulan data Tujuannya adalah untuk meningkatkan kinerja model. Hal ini mencakup pemilihan fitur yang relevan, penggabungan fitur, dan melakukan transformasi fitur. Dengan pengembangan fitur yang tepat, akurasi model dapat ditingkatkan secara signifikan. Menerapkan teknik pengoptimalan ini dapat meningkatkan performa model pembelajaran mesin yang diawasi. Dengan menggabungkan penyetelan hyperparameter, validasi silang, dan rekayasa fitur yang sesuai, Anda dapat membangun model prediktif yang sangat andal.
Mengatasi Tantangan dengan Model Prediktif
Beberapa tantangan sering muncul dalam dunia model pembelajaran mesin. Salah satunya adalah overfitting, dimana model terlalu cocok dengan data pelatihan. Hal ini membuat sulit untuk mengenali pola-pola baru. Sebaliknya jika modelnya terlalu sederhana maka akan terjadi underfitting.
Pola dalam data tidak dapat ditangkap. Bias data juga bisa menjadi masalah. Data pelatihan mungkin tidak representatif atau memiliki banyak kesalahan sistematis. Hal ini dapat menyebabkan model memprediksi hasil yang salah. Terakhir, penafsiran model ini merupakan sebuah tantangan.
Anda harus mampu memahami dan menjelaskan alasan di balik prediksi model tersebut. Untuk mengatasi masalah ini, gunakan teknik seperti penyetelan hyperparameter, validasi silang, dan rekayasa fitur. Mengatasi tantangan ini dapat meningkatkan akurasi dan keandalan model prediktif.
Alat dan Kerangka Kerja Umum
Ada banyak alat dan kerangka kerja umum untuk mengembangkan model pembelajaran mesin yang diawasi. Dua bahasa pemrograman yang umum digunakan adalah Python dan R. Library Python yang populer mencakup scikit-learn, TensorFlow, dan PyTorch Perpustakaan Pembelajaran Mesin Python scikit-learn adalah perpustakaan pembelajaran mesin Python yang sangat kuat.
Cocok untuk klasifikasi, regresi, dan pengelompokan. Pustaka ini mudah digunakan dan menyediakan alat komprehensif untuk membuat, mengevaluasi, dan menerapkan model. TensorFlow dan PyTorch adalah dua framework pembelajaran mendalam yang populer. Keduanya menyediakan alat canggih untuk membangun, melatih, dan menerapkan model jaringan saraf tingkat lanjut. Kedua framework tersebut sangat fleksibel dan cocok untuk berbagai aplikasi pembelajaran mesin.
Lingkungan Pengembangan Terpadu (IDE) Ada juga beberapa lingkungan pengembangan terintegrasi (IDE) yang populer untuk mengembangkan model pembelajaran mesin. Jupyter Notebook dan Google Colab adalah dua IDE yang populer. Menyediakan lingkungan pemrograman interaktif dan mendorong kolaborasi. Memahami alat umum ini akan membantu Anda memilih solusi terbaik untuk proyek pembelajaran mesin Anda. Ini membantu mengoptimalkan hasil yang dicapai.
Studi Kasus dan Contoh Penerapan
Bagian ini menyajikan studi kasus nyata. Ini tentang penerapan model pembelajaran mesin yang diawasi ke berbagai industri. Pelajari bagaimana model ini dapat membantu memecahkan masalah bisnis. Misalnya industri ritel. Sebuah perusahaan ritel Indonesia menggunakan model ini untuk memperkirakan permintaan produk.
Ini juga menganalisis data penjualan masa lalu untuk mengoptimalkan inventaris. Ini membantu meningkatkan akurasi prediksi. Ini juga mengurangi biaya penyimpanan yang tidak diperlukan. Sebuah contoh dari industri kesehatan juga dibahas. Sebuah rumah sakit di Jakarta menggunakan model ini untuk memprediksi risiko penyakit. Mereka menganalisis data riwayat kesehatan dan faktor risiko. Model ini membantu dokter dan staf medis memberikan pelayanan yang lebih baik Ini lebih proaktif dan rinci.
Baca Juga: DevOps Engineering: Bangun Pengembangan dan Operasional
FAQ
Apa itu model pembelajaran mesin terawasi?
Model pembelajaran mesin terawasi adalah teknik untuk membuat prediksi yang akurat. Algoritma ini dilatih menggunakan data yang sudah terlabel. Tujuannya adalah agar bisa memprediksi dengan baik pada data baru.
Apa perbedaan antara pembelajaran mesin terawasi dan tidak terawasi?
Pembelajaran mesin terawasi menggunakan data yang sudah terlabel. Sementara pembelajaran tidak terawasi menganalisis data tanpa label. Tujuan pembelajaran terawasi adalah untuk membuat prediksi, sedangkan pembelajaran tidak terawasi fokus pada eksplorasi data.
Mengapa data penting dalam pembelajaran mesin terawasi?
Data berkualitas sangat penting dalam pembelajaran mesin terawasi. Algoritma memakainya untuk belajar dan membuat prediksi yang akurat. Kualitas dan kuantitas data sangat mempengaruhi performa model.
Bagaimana proses kerja model pembelajaran mesin terawasi?
Proses kerja model pembelajaran mesin terawasi adalah sebagai berikut: 1) Data berlabel dimasukkan ke dalam model. 2) Algoritma belajar dari data tersebut. 3) Model dilatih hingga akurasi yang diinginkan tercapai. 4) Model siap digunakan untuk prediksi data baru.
Apa saja komponen utama dalam model prediksi terawasi?
Komponen utama dalam model prediksi terawasi adalah: 1) Dataset training dan testing. 2) Algoritma pembelajaran. 3) Fungsi evaluasi untuk mengukur kinerja model.
Apa saja jenis algoritma yang digunakan dalam pembelajaran mesin terawasi?
Beberapa algoritma populer dalam pembelajaran mesin terawasi adalah: Algoritma Klasifikasi dan Algoritma Regresi. Algoritma Klasifikasi termasuk Regresi Logistik, K-Nearest Neighbors, dan Decision Trees. Algoritma Regresi meliputi Regresi Linier, Regresi Polinomial, dan Support Vector Regression.
Bagaimana cara membangun model prediksi akurat?
Untuk membangun model prediksi akurat, ada beberapa langkah: 1) Pengumpulan dan persiapan data. 2) Pemilihan algoritma yang tepat. 3) Proses training dan validasi model.
Di mana saja supervised machine learning model dapat diimplementasikan?
Model pembelajaran mesin terawasi dapat diimplementasikan di berbagai industri. Misalnya, untuk prediksi penjualan, diagnosis medis, deteksi kecurangan, dan pengembangan sistem rekomendasi.
Apa teknik optimasi yang dapat diterapkan pada model prediksi terawasi?
Beberapa teknik optimasi untuk meningkatkan performa model prediksi terawasi adalah: Hyperparameter Tuning, Cross-Validation, dan Feature Engineering.
Apa saja tantangan dalam pengembangan model pembelajaran mesin terawasi?
Beberapa tantangan dalam pengembangan model pembelajaran mesin terawasi adalah: mengatasi overfitting, underfitting, bias dalam data, dan interpretasi model yang kompleks.
Apa saja tools dan framework populer untuk pembelajaran mesin terawasi?
Tools dan framework populer untuk pengembangan model pembelajaran mesin terawasi antara lain: Python Libraries seperti Scikit-learn, TensorFlow, dan PyTorch. Integrated Development Environments seperti Jupyter Notebook dan Google Colab juga populer.
Untuk mengetahui informasi lebih lengkapnya tentang programmer kunjungi website https://academy.lumoshive.com/ atau hubungi admin via Whatsapp dengan klik tombol dibawah ini